Máquinas de Vetores de Suporte (SVM): Guia Introdutório para Classificação
Uma introdução às Máquinas de Vetores de Suporte (SVM), explorando conceitos como dimensão VC, hiperplanos, vetores de suporte, margens flexíveis, truque do kernel e classificação multiclasse.
A Máquina de Vetores de Suporte, do inglês Support Vector Machine (SVM), é um algoritmo versátil amplamente utilizado em problemas de classificação e regressão. Neste post, o foco será compreender intuitivamente como o SVM funciona em tarefas de classificação.
A proposta aqui é apresentar os principais conceitos do algoritmo de forma acessível, evitando demonstrações matemáticas excessivamente formais. O objetivo não é esgotar o tema, mas construir uma intuição sólida sobre a lógica por trás do SVM, desde a ideia de separação por hiperplanos até o uso do truque do kernel.
Ao final da leitura, você terá uma visão clara do propósito do algoritmo, de suas principais características e do contexto em que ele costuma ser aplicado.
Dimensão Vapnik-Chervonenkis (VC):
A dimensão Vapnik-Chervonenkis (VC) é uma medida utilizada para quantificar a capacidade de representação de um modelo de classificação. Em termos intuitivos, ela indica o número máximo de pontos que podem ser separados corretamente em todas as configurações possíveis (shattering) por um determinado conjunto de funções.
Esse conceito foi proposto por Vapnik e Chervonenkis em 1971 e é amplamente utilizado para analisar a flexibilidade de modelos de aprendizado estatístico. Quanto maior a dimensão VC, maior a capacidade do modelo de representar padrões complexos.
Exemplo
A dimensão VC de classificadores lineares binários em um plano bidimensional é igual a 3. Isso significa que existem configurações com 3 pontos que podem ser separadas corretamente em todas as combinações possíveis utilizando uma reta.
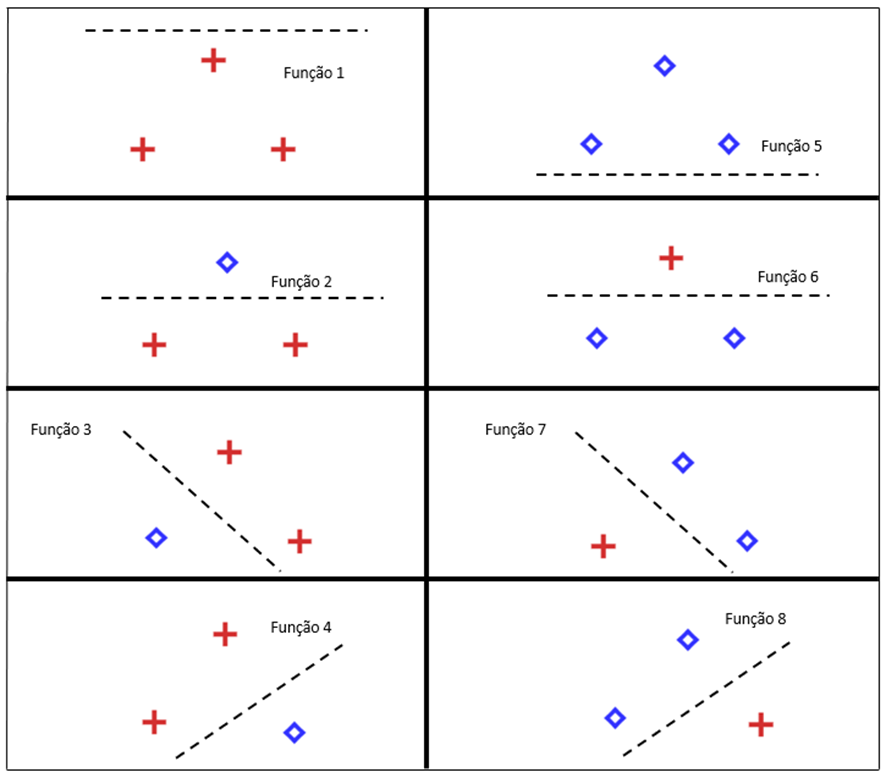
No entanto, ao utilizar 4 pontos, já existem algumas combinações que não podem ser separadas por uma única função linear.

Essa medida é importante porque modelos com VC muito alta tendem a memorizar os dados (overfitting), enquanto modelos com VC baixa demais podem não aprender padrões relevantes (underfitting).
Hiperplano
O hiperplano divide o espaço de características em regiões de decisão associadas a diferentes classes.
Um hiperplano é uma estrutura geométrica de dimensão (k-1) inserida em um espaço de dimensão (k). Em termos intuitivos:
- em um espaço bidimensional, um hiperplano corresponde a uma reta;
- em um espaço tridimensional, corresponde a um plano.
- em dimensões maiores, é a generalização dessas ideias.

Conectando com o tópico anterior, classificadores lineares definidos por hiperplanos em um espaço de dimensão (K) possuem dimensão VC igual a (K + 1). Isso ajuda a compreender a capacidade desses modelos em separar diferentes configurações de dados.
Em muitos problemas de classificação, existem diversos hiperplanos capazes de separar corretamente as classes:
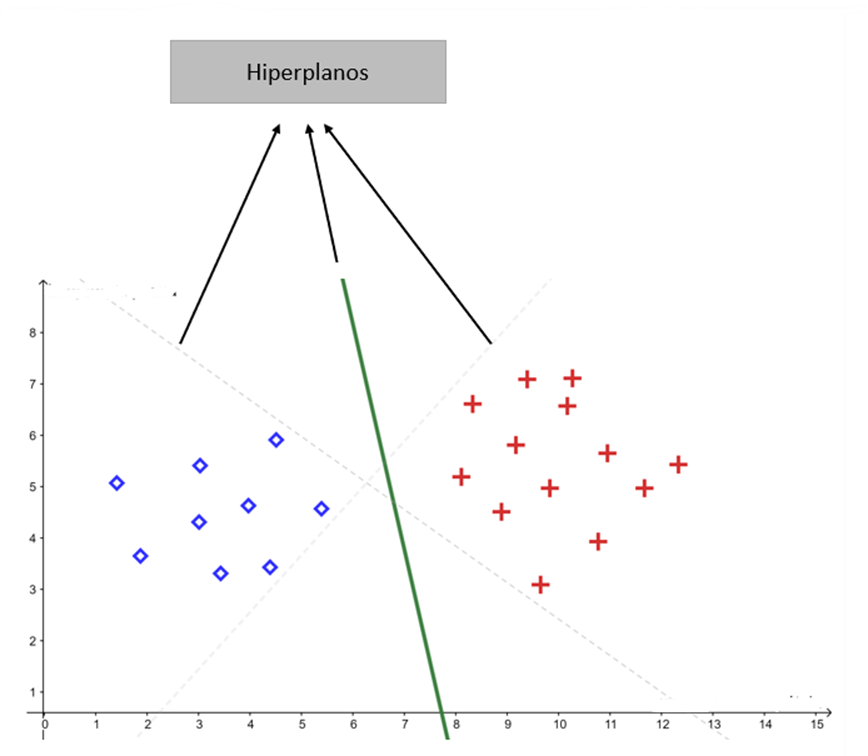
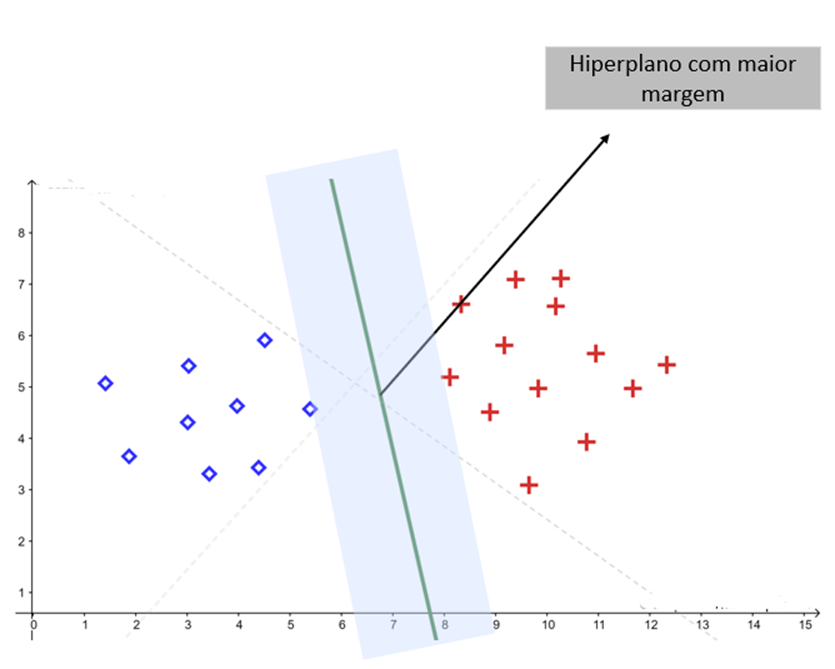
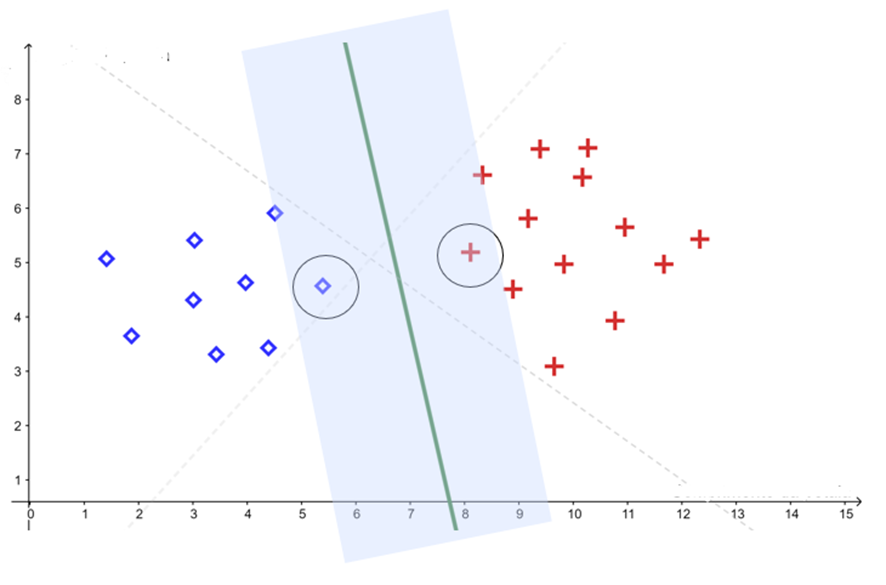
O objetivo do SVM é encontrar o hiperplano que maximiza a margem de separação entre as classes. Em outras palavras, o algoritmo procura a fronteira de decisão mais distante possível dos pontos de ambas as categorias.
Uma margem grande funciona como um “colchão de segurança”: quanto maior ela é, mais robusto o classificador tende a ser diante de ruídos e novos exemplos.
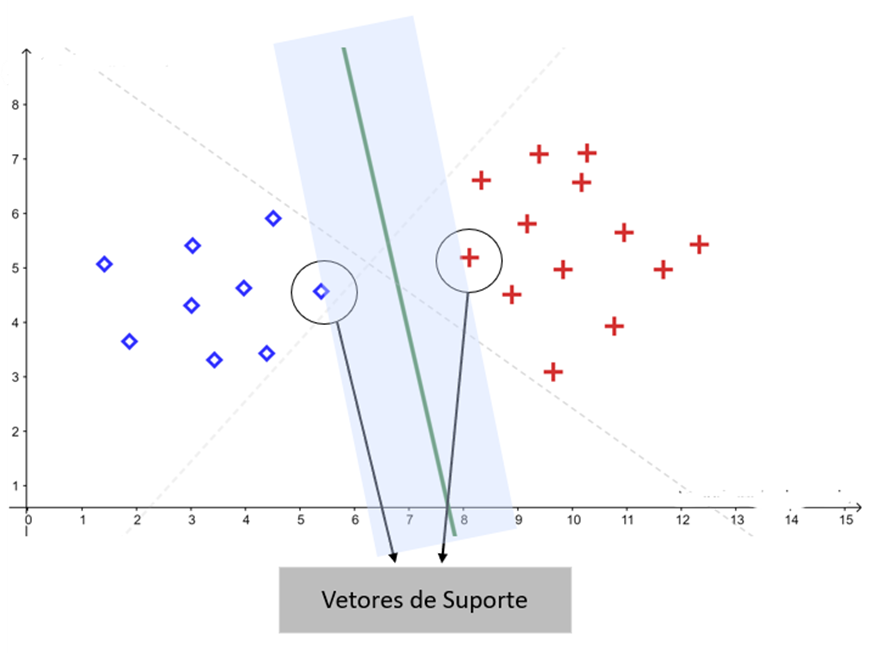
Vetores de Suporte
Os vetores de suporte são os pontos de dados mais próximos do hiperplano de separação. São eles que definem a margem máxima do classificador e, consequentemente, influenciam diretamente a posição do hiperplano ótimo encontrado pelo SVM.
Esses pontos são chamados de “vetores de suporte” porque sustentam a fronteira de decisão do modelo. Em termos práticos, pequenas alterações nesses pontos podem modificar significativamente o hiperplano obtido.
Uma característica importante do SVM é que apenas os vetores de suporte participam diretamente da definição da solução final. Pontos mais distantes da fronteira possuem pouca ou nenhuma influência no hiperplano ótimo.
Margens Suaves
Em muitos problemas reais, os dados não são perfeitamente separáveis por um hiperplano. Para lidar com esse cenário, o SVM pode utilizar margens suaves (soft margins), permitindo que alguns pontos invadam a margem de separação ou até mesmo sejam classificados incorretamente.
Essa flexibilização reduz a rigidez do modelo e ajuda a evitar o overfitting, tornando o classificador mais robusto diante de ruídos e dados atípicos.
O SVM busca, então, um equilíbrio entre:
- maximizar a margem de separação;
- minimizar os erros de classificação.
Esse equilíbrio é controlado pelo hiperparâmetro C:
C alto → penaliza fortemente erros → margem rígida → risco de overfitting
C baixo → tolera violações → margem mais suave → maior generalização
Mas o que acontece quando os dados não podem ser separados linearmente?
Dados Não Lineares e o Teorema de Cover
O Teorema de Cover afirma que padrões complexos possuem maior probabilidade de se tornarem linearmente separáveis quando projetados em espaços de maior dimensionalidade, desde que esses espaços não estejam excessivamente preenchidos.
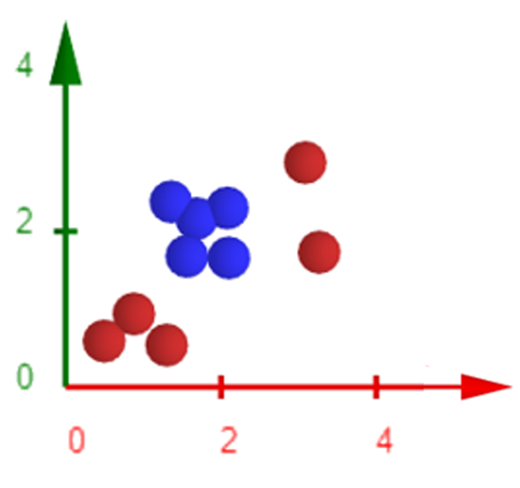
Com base nessa ideia, podemos aplicar transformações nos dados para mapeá-los em um novo espaço de características de dimensão mais elevada. Por exemplo, uma transformação como:
\[(x, y) \rightarrow (x^2, \sqrt(2)xy, y^2)\]pode tornar separável um conjunto que originalmente não era linearmente separável.
Após essa transformação, torna-se possível aplicar um SVM linear no novo espaço de características.
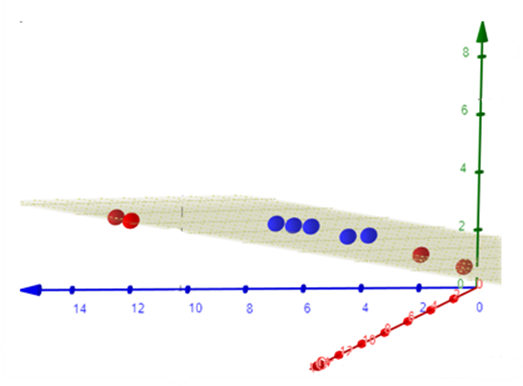
Entretanto, trabalhar explicitamente em espaços de alta dimensionalidade pode ser computacionalmente caro. Esse problema motivou o desenvolvimento do chamado truque do kernel, que permite realizar essas transformações de forma implícita e eficiente.
Truque do Kernel
O truque do kernel (kernel trick) é uma técnica que permite ao SVM trabalhar implicitamente em espaços de alta dimensionalidade sem precisar calcular explicitamente o mapeamento dos dados para esse novo espaço de características.
A ideia central é simples: em vez de transformar diretamente os pontos para uma dimensão maior, calcula-se apenas o produto interno entre eles nesse espaço transformado.
Pelo Teorema de Mercer, determinadas funções kernel podem ser interpretadas como produtos internos em um espaço de características de maior dimensão, desde que satisfaçam propriedades matemáticas específicas, como gerar matrizes simétricas e positivas semidefinidas.
Exemplo: Kernel Polinomial Quadrático
Considere o seguinte kernel:
\[K(\mathbf{w}, \mathbf{q}) = (\mathbf{w}^T \mathbf{q})^2\]Expandindo o produto interno:
\[= (x_1x_2 + y_1y_2)^2\] \[= x_1^2x_2^2 + 2x_1x_2y_1y_2 + y_1^2y_2^2\]Esse resultado pode ser reescrito como:
\[= \phi(\mathbf{w})^T \phi(\mathbf{q})\]onde:
\[\phi(x,y) = (x^2,\sqrt{2}xy,y^2)\]Ou seja, o kernel realiza implicitamente o cálculo do produto interno em um espaço de maior dimensão, sem que seja necessário computar explicitamente a transformação $ (\phi) $ .
Isso torna o treinamento computacionalmente mais eficiente, especialmente quando trabalhamos com espaços de características muito grandes.
Tipos de Kernel
Existem diversos tipos de funções kernel utilizadas em SVM, entre as mais conhecidas:
- Kernel Linear;
- Kernel Polinomial;
- Kernel Radial (RBF);
- Kernel Sigmoide (Tangente Hiperbólica).
Cada kernel define implicitamente uma forma diferente de transformação do espaço de características.
Principais Funções Kernel
Kernel Polinomial
O kernel polinomial permite representar fronteiras de decisão não lineares por meio de combinações polinomiais entre os atributos.
\[K(\mathbf{x}, \mathbf{y}) = (\gamma \mathbf{x}^T \mathbf{y} + c)^d\]onde:
- $ (d) $ define o grau do polinômio;
- $ (\gamma) $ controla a influência dos dados;
- $ (c) $ é uma constante de ajuste.
Kernel Radial (RBF)
O kernel radial (Radial Basis Function) é um dos mais utilizados em SVM devido à sua capacidade de modelar relações altamente não lineares.
\[K(\mathbf{x}, \mathbf{y}) = e^{-\gamma \|\mathbf{x}-\mathbf{y}\|^2}\]Esse kernel mede similaridade com base na distância euclidiana entre os pontos: quanto mais próximos eles estão, maior tende a ser o valor do kernel.
Kernel Sigmoide (Tangente Hiperbólica)
O kernel sigmoide possui comportamento semelhante ao de neurônios artificiais utilizados em redes neurais.
\[K(\mathbf{x}, \mathbf{y}) = \tanh(\gamma \mathbf{x}^T \mathbf{y} + c)\]Seu uso é menos comum em comparação aos kernels polinomial e radial.
Mas o que acontece quando temos mais de duas classes?
Classificação SVM Multiclasse
O SVM foi originalmente desenvolvido para problemas de classificação binária. Entretanto, diversas estratégias permitem estender sua utilização para cenários com múltiplas classes.
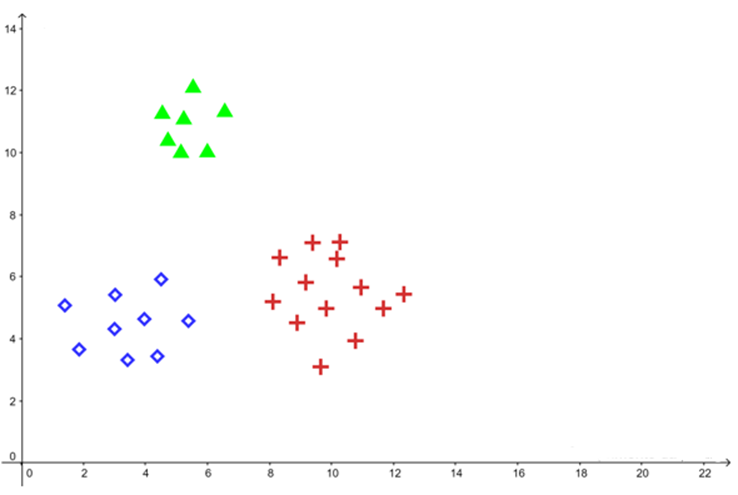
Entre os principais métodos utilizados, destacam-se:
Um-contra-todos (One-vs-Rest)
Nesse método, um classificador é treinado para separar uma classe específica de todas as demais. O processo é repetido para cada classe do problema.
Por exemplo, em um problema com três classes (A), (B) e (C), seriam treinados três classificadores:
- (A) versus ((B,C));
- (B) versus ((A,C));
- (C) versus ((A,B)).
Um-contra-um (One-vs-One)
Nesse caso, um classificador é treinado para cada par possível de classes.
Em um problema com três classes, seriam treinados classificadores para:
- (A) versus (B);
- (A) versus (C);
- (B) versus (C).
A decisão final normalmente ocorre por votação entre os classificadores.
DAG-SVM
O DAG-SVM (Directed Acyclic Graph SVM) organiza múltiplos classificadores binários em uma estrutura em grafo acíclico direcionado baseada em classificações binárias sequenciais.
A cada etapa, uma classe é eliminada até que reste apenas a classe final atribuída ao exemplo.
Referências:
Shalev-Shwartz, Shai, and Shai Ben-David. Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014. [link]
Faceli, Katti. Inteligência artificial: uma abordagem de aprendizado de máquina. Grupo Gen - LTC, 2011.
Cover, Thomas M. “Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition.” IEEE Transactions on Electronic Computers, vol. EC-14, no. 3, June 1965, pp. 326–34. DOI.org (Crossref), https://doi.org/10.1109/PGEC.1965.264137. [link]
Chih-Wei Hsu and Chih-Jen Lin. “A Comparison of Methods for Multiclass Support Vector Machines.” IEEE Transactions on Neural Networks, vol. 13, no. 2, Mar. 2002, pp. 415–25. DOI.org (Crossref), https://doi.org/10.1109/72.991427.
Platt, John and Cristianini, Nello and Shawe-Taylor, John. “Large Margin DAGs for Multiclass Classification”. Advances in Neural Information Processing Systems, MIT Press, vol.12, 1999. [link]
V.N. Vapnik and A.Ya. Chervonenkis. Theory of Pattern Recognition. Nauka, Moscow, 1974. (in Russian); German translation: Theorie der Zeichenerkennung, Akademie Verlag, Berlin, 1979.